Programmers Guide
This guide is intended for programmers who develop applications targeted for AtomVM.
As an implementation of the Erlang virtual machine, AtomVM is designed to execute unmodified byte-code instructions compiled into BEAM files, either by the Erlang or Elixir compilers. This allow developers to write programs in their BEAM programming language of choice, and to use the common Erlang community tool-chains specific to their language platform, and to then deploy those applications onto the various devices that AtomVM supports.
This document describes the development workflow when writing AtomVM applications, as well as a high-level overview of the various APIs that are supported by AtomVM. With an understanding of this guide, you should be able to design, implement, and deploy applications onto a device running the AtomVM virtual machine.
AtomVM Features
Currently, AtomVM implements a strict subset of the BEAM instruction set.
A high level overview of the supported language features include:
All the major Erlang types, including
support for many Erlang BIFs and guard expressions to support the above types
pattern matching (case statements, function clause heads, etc)
try ... catch ... finallyconstructsanonymous functions
process
spawnandspawn_linksend (
!) andreceivemessagesbit syntax (with some restrictions)
reference counted binaries
stacktraces
symmetric multi-processing (SMP)
In addition, several features are supported specifically for integration with micro-controllers, including:
Wifi networking (
network)Peripheral and system support on micro-controllers, including
Limitations
While the list of supported features is long and growing, the currently unsupported Erlang/OTP and BEAM features include (but are not limited to):
Atoms. Atoms larger than 255 bytes (255 ascii characters) are not supported.
Bignums. Integer values are restricted to 64-bit values.
Bit Syntax. While packing and unpacking of arbitrary (but less than 64-bit) bit values is supported, packing and unpacking of integer values at the start or end of a binary, or bordering binary packing or extraction must align on 8-bit boundaries. Arbitrary bit length binaries are not currently supported.
The
epmdand thedisterlprotocols are not supported.There is no support for code hot swapping.
There is no support for a Read-Eval-Print-Loop. (REPL)
Numerous modules and functions from Erlang/OTP standard libraries (
kernel,stdlib,sasl, etc) are not implemented.
AtomVM bit syntax is restricted to alignment on 8-bit boundaries. Little-endian and signed insertion and extraction of integer values is restricted to 8, 16, and 32-bit values. Only unsigned big and little endian 64-bit values can be inserted into or extracted from binaries.
It is highly unlikely that an existing Erlang program targeted for Erlang/OTP will run unmodified on AtomVM. And indeed, even as AtomVM matures and additional features are added, it is more likely than not that Erlang applications will need to targeted specifically for the AtomVM platform. The intended target environment (small, cheap micro-controllers) differs enough from desktop or server-class systems in both scale and APIs that special care and attention is needed to target applications for such embedded environments.
That being said, many of the features of the BEAM are supported and provide a rich and compelling development environment for embedded devices, which Erlang and Elixir developers will find natural and productive.
AtomVM Development
This section describes the typical development environment and workflow most AtomVM developers are most likely to use.
Development Environment
In general, for most development purposes, you should be able to get away with an Erlang/OTP development environment, and for Elixir developers, and Elixir development environment. For specific version requirements, see the Release Notes.
We assume most development will take place on some UNIX-like environment (e.g., Linux, FreeBSD, or MacOS). Consult your local package manager for installation of these development environments.
Developers will want to make use of common Erlang or Elixir development tools, such as rebar3 for Erlang developers or mix for Elixir developers.
Developers will need to make use of some AtomVM tooling. Fortunately, there are several choices for developers to use:
AtomVM
PackBEAMexecutable (described below)atomvm_rebar3_plugin, for Erlang development usingrebar3.
Some testing can be performed on UNIX-like systems, using the AtomVM executable that is suitable for your development environment. AtomVM applications that do not make use of platform-specific APIs are suitable for such tests.
Deployment and testing on micro-controllers is slightly more involved, as these platforms require additional hardware and software, described below.
ESP32 Deployment Requirements
In order to deploy AtomVM applications to and test on the ESP32 platform, developers will need:
A computer running MacOS or Linux (Windows support is TBD);
An ESP32 module with a USB/UART connector (typically part of an ESP32 development board);
A USB cable capable of connecting the ESP32 module or board to your development machine (laptop or PC);
The
esptoolprogram, for flashing the AtomVM image and AtomVM programs;(Optional, but recommended) A serial console program, such as
minicomorscreen, so that you can view console output from your AtomVM application.
STM32 Deployment Requirements
A computer running MacOS or Linux (Windows is not currently supported);
An stm32 board with a USB/UART connector (these are built into some boards such as the Nucleo product line) and a minimum of 512k (1M recommended) of flash and a minimum of 100k RAM;
A USB cable capable of connecting the STM32 board or external UART connector to your development machine (laptop or PC);
st-flashvia stlink, to flash both AtomVM and your packed AVM applications. Make sure to follow its installation procedure before proceeding further.packbeamthe AtomVM for packing and stripping*.beamfiles into the AtomVM*.avmformat.(Optional, but recommended) A serial console program, such as
minicomorscreen, so that you can view console output from your AtomVM application.
Raspberry Pi RP2 Deployment Requirements
A computer running MacOS or Linux (Windows support is not currently supported);
A board with a Raspberry Pi RP2 soc such as Raspberry Pi Pico or Pico W or Pico 2, with a USB connector (typically part of a development board);
A USB cable capable of connecting the module or board to your development machine (laptop or PC);
(Optional, but recommended) A serial console program, such as
minicomorscreen, so that you can view console output from your AtomVM application.
Development Workflow
For the majority of users, AtomVM applications are written in the Erlang or Elixir programming language. These applications are compiled to BEAM (.beam) files using standard Erlang or Elixir compiler tool chains (erlc, rebar3, mix, etc). The generated BEAM files contain byte-code that can be executed by the Erlang/OTP runtime, or by the AtomVM virtual machine.
Note
In a small number of cases, it may be useful to write parts of an application in the C programming language, as AtomVM nifs or ports. However, writing AtomVM nifs and ports is outside of the scope of this document.
Once Erlang and/or Elixir files are compiled to BEAM files, AtomVM provides tooling for processing and aggregating BEAM files into AtomVM Packbeam (.avm) files, using AtomVM tooling, distributed as part of AtomVM, or as provided through the AtomVM community.
AtomVM packbeam files are the applications and libraries that run on the AtomVM virtual machine. For micro-controller devices, they are “flashed” or uploaded to the device; for command-line use of AtomVM (e.g., on Linux, FreeBSD, or MacOS), they are supplied as the first parameter to the AtomVM command.
The following diagram illustrates the typical development workflow, starting from Erlang or Elixir source code, and resulting in a deployed Packbeam file:
*.erl or *.ex *.beam
+-------+ +-------+
| |+ | |+
| ||+ | ||+
| ||| --------> | |||
| ||| Erlang/Elixir | |||
+-------+|| Compiler +-------+||
+-------+| +-------+|
+-------+ +-------+
^ |
| | packbeam
| |
| v
| +-------+
| | |
| test | |
| debug | |
| fix | |
| +-------+
| app.avm
| |
| | flash/upload
| |
| v
+-------------------- Micro-controller
device
The typical compile-test-debug cycle can be summarized in the following steps:
Deploy the AtomVM virtual machine to your device
Develop an AtomVM application in Erlang or Elixir
Write application
Deploy application to device
Test/Debug/Fix application
Repeat
Deployment of the AtomVM virtual machine and an AtomVM application currently require a USB serial connection. There is currently no support for over-the-air (OTA) updates.
For more information about deploying the AtomVM image and AtomVM applications to your device, see the Getting Started Guide
Applications
An AtomVM application is a collection of BEAM files, aggregated into an AtomVM “Packbeam” (.avm) file, and typically deployed (flashed) to some device. These BEAM files be be compiled from Erlang, Elixir, or any other language that targets the Erlang VM.
Attention
The return value from the start/0 function is ignored on the the generic_unix platform, most MCU platforms have
the option of rebooting the device if the start/0 function returns a value other than ok. Consult the
Build Instructions for your device to see how this
is configured.
Here, for example is one of the smallest AtomVM applications you can write:
-module(myapp).
-export([start/0]).
start() ->
ok.
This particular application doesn’t do much, of course. The application will start and immediately terminate, with a return value of ok. Typical AtomVM applications will be more complex than this one, and the AVM file that contains the application BEAM files will be considerably larger and more complex than the above program.
Most applications will spawn processes, send and receive messages between processes, and
wait for certain conditions to apply before terminating, if they terminate at all. For applications
that spawn processes and run forever, you may need to add an empty receive ... end block, to
prevent the AtomVM from terminating prematurely, e.g.,
wait_forever() ->
receive X -> X end.
Packbeam files
AtomVM applications are packaged into Packbeam (.avm) files, which contain collections of files, typically BEAM (.beam) files that have been generated by the Erlang or Elixir compiler.
At least one BEAM module in this file must contain an exported start/0 function. The first module in a Packbeam file that contain this function is the entry-point of your application and will be executed when the AtomVM virtual machine starts.
Not all files in a Packbeam need to be BEAM modules – you can embed any type of file in a Packbeam file, for consumption by your AtomVM application.
See also
The Packbeam format is described in more detail in the AtomVM PackBEAM format.
The AtomVM community has provided several tools for simplifying your experience, as a developer. These tools allow you to use standard Erlang and Elixir tooling (such as rebar3 and mix) to build Packbeam files and deploy then to your device of choice.
packbeam tool
The packbeam tool is a command-line application that can be used to create Packbeam files from a collection of input files:
$ packbeam help
packbeam version 0.7.0
Syntax:
packbeam <sub-command> <options> <args>
The following sub-commands are supported:
create <options> <output-avm-file> [<input-file>]+
where:
<output-avm-file> is the output AVM file,
[<input-file>]+ is a list of one or more input files,
and <options> are among the following:
[--prune|-p] Prune dependencies
[--start|-s <module>] Start module
[--remove_lines|-r] Remove line number information from AVM files
list <options> <avm-file>
where:
<avm-file> is an AVM file,
and <options> are among the following:
[--format|-f csv|bare|default] Format output
extract <options> <avm-file> [<element>]*
where:
<avm-file> is an AVM file,
[<element>]+ is a list of one or more elements to extract
(if empty, then extract all elements)
and <options> are among the following:
[--out|-o <output-directory>] Output directory into which to write elements
(if unspecified, use the current working directory)
delete <options> <avm-file> [<element>]+
where:
<avm-file> is an AVM file,
[<element>]+ is a list of one or more elements to delete,
and <options> are among the following:
[--out|-o <output-avm-file>] Output AVM file
version
Print version and exit
help
Print this help
For more information consult the packbeam section of AtomVM Tooling.
Running AtomVM
AtomVM is executed in different ways, depending on the platform. On most microcontrollers (e.g., the ESP32), the VM starts when the device is powered on. On UNIX platforms, the VM is started from the command-line using the AtomVM executable.
AtomVM will use the first module in the supplied AVM file that exports a start/0 function as the entrypoint for the application.
AtomVM program syntax
On UNIX platforms, you can specify a BEAM file or AVM file as the first argument to the executable, e.g.,
$ AtomVM foo.avm
Important
If you start the AtomVM executable with a BEAM file, then the corresponding module may not make any calls to
external function in other modules, with the exception of built-in functions and Nifs that are included in the VM.
Core APIs
The AtomVM virtual machine provides a set of Erlang built-in functions (BIFs) and native functions (NIFs), as well as a collection of Erlang and Elixir libraries that can be used from your applications.
This section provides an overview of these APIs. For more detailed information about specific APIs, please consult the API reference documentation.
Standard Libraries
AtomVM provides a limited implementations of standard library modules, including:
In addition AtomVM provides limited implementations of standard Elixir modules, including:
ListTupleEnumKernelModuleProcessConsole
For detailed information about these functions, please consult the API reference documentation. These modules provide a strict subset of functionality from their Erlang/OTP counterparts. However, they aim to be API-compatible with the Erlang/OTP interfaces, at least for the subset of provided functionality.
Spawning Processes
AtomVM supports the actor concurrency model that is pioneered in the Erlang/OTP runtime. As such, users can spawn processes, send messages to and receive message from processes, and can link or monitor processes to be notified if they have crashed.
To spawn a process using a defined or anonymous function, pass the function to the spawn/1 function:
Pid = spawn(fun run_some_code/0),
The function you pass may admit closures, so for example you can pass variables defined outside of the scope of the function to the anonymous function to pass into spawn/1:
Args = ...
Pid = spawn(fun() -> run_some_code_with_args(Args) end),
Alternatively, you can pass a module, function name, and list of arguments to the spawn/3 function:
Args = ...
Pid = spawn(?MODULE, run_some_code_with_args, [Args]),
The spawn_opt/2,4 functions can be be used to spawn a function with additional options that control the behavior of the spawned processes, e.g.,
Pid = spawn_opt(fun run_some_code/0, [{min_heap_size, 1342}]),
The options argument is a properties list containing optionally the following entries:
Key |
Value Type |
Default Value |
Description |
|---|---|---|---|
|
|
none |
Minimum heap size of the process. The heap will shrink no smaller than this size. |
|
|
unbounded |
Maximum heap size of the process. The heap will grow no larger than this size. |
|
|
|
Whether to link the spawned process to the spawning process. |
|
|
|
Whether to link the spawning process should monitor the spawned process. |
|
|
|
Strategy to grow the heap of the process. |
Console Output
There are several mechanisms for writing data to the console.
For common debugging, many users will find erlang:display/1 sufficient for debugging:
erlang:display({foo, [{bar, tapas}]}).
The output parameter is any Erlang term, and a newline will be appended automatically.
Users may prefer using the io:format/1,2 functions for more controlled output:
io:format("The ~p did a ~p~n", [friddle, frop]).
Tip
The io_lib module can be used to format string data, as well.
Logging
AtomVM supports a subset of the OTP logging facility, allowing users to send log event to log handlers (by default, the console), and to install handlers that handle log events.
To log events, you are encouraged to use the logging macros from the OTP kernel application. You can use these macros at compile time, and the generated code can be run in AtomVM.
For example:
-include_lib("kernel/include/logger.hrl").
...
?LOG_NOTICE("Something happened that might require your attention: ~p", [TheThing])
By default, this will result in a message displayed on the console, with a timestamp, log level, PID of the process that initiated the log message, the module, function, and function arity, together with the supplied log message:
2023-07-04T18:34:56.387 [notice] <0.1.0> test_logger:test_default_logger/0 Something
happened that might require your attention: ThatThingThatHappened
Tip
Note that log messages need not (and generally should not) include newline separators (~n) in log format messages,
unless necessary.
Users may provide a format string, with an optional list of arguments. Alternatively, users can provide a map encapsulating a “report” in lieu of a format string. Reports provide a mechanism for supplying a set of structured data directly to log handlers (see below), without necessarily incurring the cost of formatting log messages.
As with OTP, the following ordered log levels (from high to low) are supported:
emergencycriticalalerterrorwarningnoticeinfodebug
By default, the logging facility drops any messages below notice level. To set the default log level for the logging subsystem, see the logger_manager section, below.
You can use the logger interface directly to log messages at different levels, but in general, the OTP logging macros are encouraged, as log events generated using the OTP macros include additional metadata (such as the location of the log event) you do not otherwise get using the functions in the logger module.
For example, the expression
logger:notice("Something happened that might require your attention: ~p", [TheThing])
may seem similar to using the ?LOG_NOTICE macro, but less contextual information will be included in the log event.
For more information about the OTP logging facility, see the Erlang/OTP Logging chapter.
Note
AtomVM does not currently support programmatic configuration of the logging subsystem. All changes to default
behavior should be done via the AtomVM logger_manager module (see below).
The logger_manager
In order to use the logger interface, you will need to first start the AtomVM logger_manager service.
Note
Future versions of AtomVM may automatically start the logging subsystem as part of a kernel application, but currently, this service must be managed manually.
To start the logger_manager, use the logger_manager:start_link/1 function, passing in a configuration map for the logging subsystem.
For example, the default logging framework can be started via:
{ok, _Pid} = logger_manager:start_link(#{})
Tip
The logger_manager is a registered process, so the returned Pid may be ignored.
The configuration map supplied to the logger_manager may contain the following keys:
Key |
Type |
Default |
Description |
|---|---|---|---|
|
|
|
Primary log level |
|
|
|
Log configuration |
|
|
|
Log level specific to a set of modules |
where log_level() is defined to be:
-type log_level() :: emergency | critical | alert | error | warning | notice | info | debug.
and logger_config() is defined as follows:
-type handler_id() :: default | atom().
-type handler_config() :: #{
id => atom(),
module => module(),
level => logger:level() | all | none,
config => term()
}.
-type logger_config() :: [
{handler, default, undefined} |
{
handler,
HandlerId :: handler_id(),
Handler :: module(),
HandlerConfig :: handler_config()
} |
{module_level, logger:level(), [module()]}
].
You can set the log level for all log handlers by setting the log_level in this configuration map. Any messages that are logged at levels “higher” than or equal to the configured log level will be logged by all log handlers.
The standard logger (logger_std_h) is included by default, if no default logger is specified (and if the default logger is not disabled – see below). The standard logger will output log events to the console.
You can specify multiple log handlers in the logger configuration. If a log entry is allowed for a given log level, then each log handler will handle the log message. For example, you might have a log handler that sends messages over the network to a syslog daemon, or you might have another handler that writes log messages to a file.
You can pass handler configuration int the config element of the handler_config() you specify when specifying a logger. The value of the config element can be any term and is made available to log handlers when events are logged (see below).
If the tuple {handler, default, undefined} is included in the logger configuration, the default logger will be disabled.
At most one default logger can be specified. If you want to replace the default logger (logger_std_h), then specify a logger with the handler id default.
You can specify different log levels for specific modules. For example, if you want to set the default log level for all handlers to be notice or higher, you can set the log level for a given module to info, and all info and higher messages will be logged for that module or set of modules. Conversely, you can “quiet” a module if it is particularly noisy by setting its level to something relatively high.
For more information about how to configure the logging subsystem, see the Kernel Configuration Parameters section of the OTP Logging chapter.
You can stop the logger_manager via the logger_manager:stop/0 function:
ok = logger_manager:stop()
Writing your own log handler
Additional loggers can be enabled via handler specifications. A handler module must implement and export the log/2 function, which takes a log event and a term containing the configuration for the logger handler instance.
For example:
-module(my_module).
-export([..., log/2, ...]).
log(LogEvent, HandlerConfig) ->
%% do something with the log event
%% return value is ignored
You can specify this handler in the logger_manager configuration (see above) via a stanza such as:
{handler, my_id, my_module, HandlerConfig}
A LogEvent is a map structure containing the following fields:
Key |
Type |
Description |
|---|---|---|
|
|
The time (in microseconds since the UNIX epoch) at which the log event was generated |
|
|
The log level with which the log event was generated |
|
|
The process id of the Erlang process in which the event was generated |
|
|
The message format and arguments passed when the event was generated |
|
|
Metadata passed when the event was generated. |
If the log event was generated using a logging macro, then the meta map also contains a location field with the following fields:
Key |
Type |
Description |
|---|---|---|
|
|
The path of the file in which the event was generated |
|
|
The line number in the file in which the event was generated |
|
|
The MFA of the function in which the event was generated |
The HandlerConfig is a map structure containing the id and module of the handler and is passed into the log handler via configuration of the logger_manager (see above).
Process Management
You can obtain a list of all processes in the system via erlang:processes/0:
Pids = erlang:processes().
And for each process, you can get detailed process information via the erlang:process_info/2 function:
io:format("Heap size for Pid ~p: ~p~n", [Pid, erlang:process_info(Pid, heap_size)]).
The return value is a tuple containing the key passed into the erlang:process_info/2 function and its associated value.
The currently supported keys are enumerated in the following table:
Key |
Value Type |
Description |
|---|---|---|
|
|
Number of terms (in machine words) used in the process heap |
|
|
Number of terms (in machine words) used in the process stack |
|
|
Number of unprocessed messages in the process mailbox |
|
|
Total number of bytes used by the process (estimate) |
See the word_size key in the System APIs section for information about how to find the number of bytes used in a machine word on the current platform.
External Term Format
The erlang:term_to_binary/1 function can be used to serialize arbitrary term data into and out of binary data. These operations can be useful for applications that wish to share term data over some network protocol, such as HTTP or MQTT, or wish to store serialized term data in some permanant sttorage (e.g., Non-volatile storage on ESP32 devices).
For example, to convert a term to a binary, use erlang:term_to_binary/1, e.g.,
%% erlang
Term = ...
Binary = erlang:term_to_binary(Term),
And to convert the binary back to a term, use erlang:binary_to_term/1,2, e.g.,
%% erlang
Binary = ...
{Term, _Used} = erlang:binary_to_term(Binary, [used]),
By default, AtomVM will encode all atoms using UTF-8 encoding. This encoding is the default encoding for OTP-26 and later releases.
For more information about Erlang external term format, consult the Erlang Documentation
System APIs
You can obtain system information about the AtomVM virtual machine via the erlang:system_info/1 function, which takes an atom parameter designating the desired datum. Allowable parameters include
process_countThe number of processes running in the system.port_countThe number of ports running in the system.atom_countThe number of atoms allocated in the system.word_sizeThe word size (in bytes) on the current platform (typically 4 or 8).atomvm_versionThe version of AtomVM currently running (as a binary).
For example,
io:format("Atom Count: ~p~n", [erlang:system_info(atom_count)]).
Note
Additional platform-specific information is supported, depending on the platform type. See below.
Use the atomvm:platform/0 to obtain the system platform on which your code is running. The return value of this function is an atom who’s value will depend on the platform on which your application is running.
case atomvm:platform() of
esp32 ->
io:format("I am running on an ESP32!~n");
stm32 ->
io:format("I am running on an STM32!~n");
generic_unix ->
io:format("I am running on a UNIX box!~n")
end.
Use erlang:garbage_collect/0 or erlang:garbage_collect/1 to force the AtomVM garbage collector to run on a give process. Garbage collection will in general happen automatically when additional free space is needed and is rarely needed to be called explicitly.
The 0-arity version of this function will run the garbage collector on the currently executing process.
Pid = ... %% get a reference to some pid
ok = erlang:garbage_collect(Pid).
Use the erlang:memory/1 function to obtain information about allocated memory.
Currently, AtomVM supports the following types:
Type |
Description |
|---|---|
|
Return the total amount of memory (in bytes) occupied by (reference counted) binaries |
Note
Binary data small enough to be stored in the Erlang process heap are not counted in this measurement.
System Time
AtomVM supports numerous function for accessing the current time on the device.
Use erlang:timestamp/0 to get the current time since the UNIX epoch (Midnight, Jan 1, 1970, UTC), at microsecond granularity, expressed as a triple (mega-seconds, seconds, and micro-seconds):
{MegaSecs, Secs, MicroSecs} = erlang:timestamp().
Use erlang:system_time/1 to obtain the seconds, milliseconds or microseconds since the UNIX epoch (Midnight, Jan 1, 1970, UTC):
Seconds = erlang:system_time(second).
MilliSeconds = erlang:system_time(millisecond).
MicroSeconds = erlang:system_time(microsecond).
Use erlang:monotonic_time/1 to obtain a (possibly not strictly) monotonically increasing time measurement. Use the same time units to convert to seconds, milliseconds, or microseconds:
Seconds = erlang:monotonic_time(second).
MilliSeconds = erlang:monotonic_time(millisecond).
MicroSeconds = erlang:monotonic_time(microsecond).
Caution
Note erlang:monotonic_time/1 should not be used to calculate the wall clock time, but instead should be used by
applications to compute time differences in a manner that is independent of the system time on the device, which
might change, for example, due to NTP, leap seconds, or similar operations that may affect the wall time on the
device.
Use erlang:universaltime/0 to get the current time at second resolution, to obtain the year, month, day, hour, minute, and second:
{{Year, Month, Day}, {Hour, Minute, Second}} = erlang:universaltime().
On some platforms, you can use the atomvm:posix_clock_settime/2 to set the system time. Supply a clock id (currently, the only supported clock id is the atom realtime) and a time value as a tuple, containing seconds and nanoseconds since the UNIX epoch (midnight, January 1, 1970). For example,
SecondsSinceUnixEpoch = ... %% acquire the time
atomvm:posix_clock_settime(realtime, {SecondsSinceUnixEpoch, 0})
Warning
This operation is not supported yet on the stm32 platform. On most UNIX platforms, you typically need root
permission to set the system time.
On the ESP32 platform, you can use the Wifi network to set the system time automatically. For information about how to set system time on the ESP32 using SNTP, see the Network Programming Guide.
To convert a time (in seconds, milliseconds, or microseconds from the UNIX epoch) to a date-time, use the calendar:system_time_to_universal_time/2 function. For example,
Milliseconds = ... %% get milliseconds from the UNIX epoch
{
{Year, Month, Day}, {Hour, Minute, Second}
} = calendar:system_time_to_universal_time(Milliseconds, millisecond).
Valid time units are second, millisecond, and microsecond.
Date and Time
A datetime() is a tuple containing a date and time, where a date is a tuple containing the year, month, and day (in the Gregorian calendar), expressed as integers, and a time is an hour, minute, and second, also expressed in integers.
The following Erlang type specification enumerates this type:
-type year() :: integer().
-type month() :: 1..12.
-type day() :: 1..31.
-type date() :: {year(), month(), day()}.
-type gregorian_days() :: integer().
-type day_of_week() :: 1..7.
-type hour() :: 0..23.
-type minute() :: 0..59.
-type second() :: 0..59.
-type time() :: {hour(), minute(), second()}.
-type datetime() :: {date(), time()}.
Erlang/OTP uses the Christian epoch to count time units from year 0 in the Gregorian calendar. The, for example, the value 0 in Gregorian seconds represents the date Jan 1, year 0, and midnight (UTC), or in Erlang terms, {{0, 1, 1}, {0, 0, 0}}.
Attention
AtomVM is currently limited to representing integers in at most 64 bits, with one bit representing the sign bit. However, even with this limitation, AtomVM is able to resolve microsecond values in the Gregorian calendar for over 292,000 years, likely well past the likely lifetime of an AtomVM application (unless perhaps launched on a deep space probe).
The calendar module provides useful functions for converting dates to Gregorian days, and date-times to Gregorian seconds.
To convert a date() to the number of days since January 1, year 0, use the calendar:date_to_gregorian_days/1 function, e.g.,
GregorianDays = calendar:date_to_gregorian_days({2023, 7, 23})
To convert a datetime() to convert the number of seconds since midnight January 1, year 0, use the calendar:datetime_to_gregorian_seconds/1 function, e.g.,
GregorianSeconds = calendar:datetime_to_gregorian_seconds({{2023, 7, 23}, {13, 31, 7}})
Warning
The calendar module does not support year values before year 0.
Miscellaneous APIs
Use atomvm:random/0 to generate a random unsigned 32-bit integer in the range 0..4294967295:
RandomInteger = atomvm:random().
Use crypto:strong_rand_bytes/1 to return a randomly populated binary of a specified size:
RandomBinary = crypto:strong_rand_bytes(32).
Use base64:encode/1 and base64:decode/1 to encode to and decode from Base64 format. The input value to these functions may be a binary or string. The output value from these functions is an Erlang binary.
Encoded = base64:encode(<<"foo">>).
<<"foo">> = base64:decode(Encoded).
You can Use base64:encode_to_string/1 and base64:decode_to_string/1 to perform the same encoding, but to return values as Erlang list structures, instead of as binaries.
StackTraces
You can obtain information about the current state of a process via stacktraces, which provide information about the location of function calls (possibly including file names and line numbers) in your program.
Currently in AtomVM, stack traces can be obtained in one of following ways:
via try-catch blocks
via catch blocks, when an error has been raised via the
errorBif.
Note
AtomVM does not support erlang:get_stacktrace/0 which was deprecated in Erlang/OTP 21 and 22, stopped working in
Erlang/OTP 23 and was removed in Erlang/OTP 24. Support for accessing the current stacktrace via
erlang:process_info/2 may be added in the future.
For example a stack trace can be bound to a variable in the catch clause in a try-catch block:
try
do_something()
catch
_Class:_Error:Stacktrace ->
io:format("Stacktrace: ~p~n", [Stacktrace])
end
Alternatively, a stack trace can be bound to the result of a catch expression, but only when the error is raised by the error Bif. For example,
{'EXIT', {foo, Stacktrace}} = (catch error(foo)),
io:format("Stacktrace: ~p~n", [Stacktrace])
Stack traces are printed to the console in a crash report, for example, when a process dies unexpectedly.
Stacktrace data is represented as a list of tuples, each of which represents a stack “frame”. Each tuple is of the form:
[{Module :: module(), Function :: atom(), Arity :: non_neg_integer(), AuxData :: aux_data()}]
where aux_data() is a (possibly empty) properties list containing the following elements:
[{file, File :: string(), line, Line :: pos_integer()}]
Stack frames are ordered from the frame “closest“ to the point of failure (the “top” of the stack) to the frame furthest from the point of failure (the “bottom” of the stack).
Stack frames will contain file and line information in the AuxData list if the BEAM files (typically embedded in AVM files) include <<“Line”>> chunks generated by the compiler. Otherwise, the AuxData will be an empty list.
Tip
Adding line information to BEAM files not only increases the size of BEAM files in storage, but calculation of file and line information can have a non-negligible impact on memory usage. Memory-sensitive applications should consider not including line information in BEAM files.
The packbeam tool does include file and line information in the AVM files it creates by default, but file and line information can be omitted via a command line option. For information about the packbeam too, see the atomvm_packbeam tool.
ETS Tables
AtomVM includes a limited implementation of the Erlang ets interface, allowing applications to efficiently store term data in a potentially shared key-value store. Conceptually, and ETS table is a collection of key-value pairs (represented as Erlang tuples), which can be efficiently stored, retrieved, and deleted using insertion, lookup, and deletion functions across processes. Storage and retrieval of data in ETS tables is typically faster than communicating with a process which stores state, but still comes at a cost of copying data in and out of the ETS tables.
The current AtomVM implementation of ETS is limited to the set table type, meaning that all entries in an ETS table are unique, and that the entries in the ETS table are unordered, when enumerated.
The
ordered_set,bag, andduplicate_bagOTP ETS types are not currently supported.
The lifecycle of an ETS table is associated with the lifecycle of the Erlang process that created it. An Erlang process may create as many ETS tables as memory permits, but ETS tables are automatically destroyed when the process with which they are associated terminates.
Note. AtomVM does not currently support transfer of ETS table ownership across processes.
To create an ETS table, use the ets:new/2 function:
TableId = ets:new(my_table, [])
The first argument is the table name, which may be optionally registered internally. The second parameter is a list of configuration options. The return value is an opaque reference to the table, which can be used in subsequent ETS operations. If the table is specified as a named table (see below), then the return value is the atom used to name the table (i.e., the first parameter to the ets:new/2 function).
The process that creates an ETS table becomes the “owner” of the ETS table. ETS tables owned by a process are automatically destroyed when the process terminates.
The following configuration options are supported:
Access Type |
Description |
|---|---|
|
If set, the table name is registered internally and can be used as the table id for subsequent ETS operations. If this option is set, the return value from |
|
The position of the key field in table entries (Erlang tuples). Key position values should be in the range |
|
Only the owning process may read from or write to the ETS table. |
|
The owning process may read and write to the ETS table; any other process can only read from the ETS table. |
|
Any process may read from or write to the ETS table. |
Note that the keypos, private, protected, and public fields should only be specified once in configuration. The presence of more than one key position or protection field results in behavior that is undefined.
In the absence of any protection field, tables are marked protected.
To insert an entry into an ETS table, use the ets:insert/2 function:
true = ets:insert(TableId, {foo, bar})
Specify the table identifier returned from ets:new/2, as well as the tuple data you would like to store in the ETS table. The keypos’th field of the tuple can be used for subsequent retrieval or deletion.
If the arity of the supplied tuple entry is less than the configured key position for the ETS table, the ets:insert/2 function will raise a badarg error.
Note that the fields of a tuple entry, whether they are designated key fields or arbitrary data, can be any term type, not just atoms, as in this example.
If an entry already exists with the same key field, the entry will be over-written in the table.
The return type from this function is the atom true. Any errors in insertion will resulting in raising an error with an appropriate reason, e.g., badarg.
Note that a process may only insert values into an ETS table if they are permitted; i.e., either they are the owner of the table, or if the table is
public.
To retrieve an entry from an ETS table, use the ets:lookup/2 function:
[{foo, bar}] = ets:lookup(TableId, foo)
Specify the table identifier returned from ets:new/2, as well as a key with which you would like to search the table. This function will search the ETS table using the keypos’th field of tuples in the ETS table for retrieval.
The return value is a list containing the found object(s). An empty list ([]) indicates that there is no such entry in the specified ETS table.
Note. Since the only table type currently supported is
set, the return value will only contain a singleton value, if an entry exists in the table under the specified key.
Note that a process may only look up values from an ETS table if they are permitted; i.e., either they are the owner of the table, or if the table is
protectedorpublic.
To delete an entry from an ETS table, use the ets:delete/2 function:
true = ets:delete(Table, foo)
Specify the table identifier returned from ets:new/2, as well as a key with which you would like to search the table to delete the entry. This function will search the ETS table using the keypos’th field of tuples in the ETS table for retrieval.
The return value from this function is the atom true, regardless of whether the entry existed previously. Any errors in deletion will resulting in raising an error with an appropriate reason, e.g., badarg.
Note that a process may only delete values from an ETS table if they are permitted; i.e., either they are the owner of the table, or if the table is
public.
Reading data from AVM files
AVM files are generally packed BEAM files, but they can also contain non-BEAM files, such as plain text files, binary data, or even encoded Erlang terms.
Typically, these files are included from the priv directory in a build tree, for example, when using the atomvm_rebar3_plugin, though the atomvm_packbeam tool allow you to specify any location for files to include in AVM files.
By convention, these files obey the following path in an AVM file:
<application-name>/priv/<file-path>
For example, if you wanted to embed my_file.txt into your application AVM file (where your application name is, for example, my_application), you would use:
my_application/priv/my_file.txt
The atomvm:read_priv/2 function can then be used to extract the contents of this file into a binary, e.g.,
MyFileBin = atomvm:read_priv(my_application, <<"my_file.txt">>)
Tip
Embedded files may contain path separators, so for example <<"my_files/my_file.txt">> would be used if the AVM
file embeds my_file.txt using the path my_application/priv/my_files/my_file.txt
For more information about how to embed files into AVM files, see the atomvm_rebar3_plugin, and the atomvm_rebar3_plugin section of the AtomVM Tooling guide.
Code Loading
AtomVM provides a limited set of APIs for loading code and data embedded dynamically at runtime.
To load an AVM file from binary data, use the atomvm:add_avm_pack_binary/2 function. Supply a reference to the AVM data, together with a (possibly empty) list of options. Specify a name option, whose value is an atom, if you wish to close the AVM data at a later point in the program.
For example:
AVMData = ... %% load AVM data into memory as a binary
ok = atomvm:add_avm_pack_binary(AVMData, [{name, my_avm}])
You can also load AVM data from a file (on the generic_unix platform) or from a flash partition (on ESP32 platforms) using the atomvm:add_avm_pack_file/2 function. Specify a string (or binary) as the path to the AVM file, together with a list of options, such as name.
For example:
ok = atomvm:add_avm_pack_file("/path/to/file.avm", [{name, my_avm}])
On esp32 platforms, the partition name should be prefixed with the string /dev/partition/by-name/. Thus, for example, if you specify /dev/partition/by-name/main2.avm as the partition, the ESP32 flash should contain a data partition with the name main2.avm
For example:
ok = atomvm:add_avm_pack_file("/dev/partition/by-name/main2.avm", [])
To close a previous opened AVM by name, use the atomvm:close_avm_pack/2 function. Specify the name of the AVM pack used to add
ok = atomvm:close_avm_pack(my_avm, [])
Important
Currently, the options parameter is ignored, so use the empty list ([]) for forward compatibility.
You can load an individual BEAM file using the code:load_binary/3 function. Specify the Module name (as an atom), as well as the BEAM data you have loaded into memory.
For Example:
BEAMData = ... %% load BEAM data into memory as a binary
{module, Module} = code:load_binary(Module, Filename, BEAMData)
Attention
The Filename parameter is currently ignored.
You can load an individual BEAM file from the file system using the code:load_abs/1 function. Specify the path to the BEAM file. This path should not include the .beam extension, as this extension will be added automatically.
For example:
{module, Module} = code:load_abs("/path/to/beam/file/without/beam/extension")
Attention
This function is currently only supported on the generic_unix platform.
Math
AtomVM supports the following standard functions from the OTP math module:
cos/1acos/1acosh/1asin/1asinh/1atan/1atan2/2atanh/1ceil/1cosh/1exp/1floor/1fmod/2log/1log10/1log2/1pow/2sin/1sinh/1sqrt/1tan/1tanh/1pi/0
The input values for these functions may be float or integer types. The return value is always a value of float type.
Input values that are out of range for the specific mathematical function or which otherwise are invalid or yield an invalid result (e.g., division by 0) will result in a badarith error.
Attention
If the AtomVM virtual machine is built with floating point arithmetic support disabled, these functions will result
in a badarg error.
Cryptographic Operations
You can hash binary date using the crypto:hash/2 function.
crypto:hash(sha, [<<"Some binary">>, $\s, "data"])
This function takes a hash algorithm, which may be one of:
-type md_type() :: md5 | sha | sha224 | sha256 | sha384 | sha512.
and an IO list. The output type is a binary, who’s length (in bytes) is dependent on the algorithm chosen:
Algorithm |
Hash Length (bytes) |
|---|---|
|
16 |
|
20 |
|
32 |
|
32 |
|
64 |
|
64 |
Attention
The crypto:hash/2 function is currently only supported on the ESP32 and generic UNIX platforms.
You can also use the legacy erlang:md5/1 function to compute the MD5 hash of an input binary. The output is a fixed-length binary (16 bytes)
Hash = erlang:md5(<<foo>>).
On ESP32, you can perform symmetric encryption and decryption of any iodata data using crypto_one_time/4,5 function.
Following ciphers are supported:
Without IV (using crypto_one_time/4):
aes_128_ecbaes_192_ecbaes_256_ecb
With IV (using crypto_one_time/5):
aes_128_cbcaes_192_cbcaes_256_cbcaes_128_cfb128aes_192_cfb128aes_256_cfb128aes_128_ctraes_192_ctraes_256_ctr
The function is implemented using mbedTLS, so please to its documentation for further details.
Please refer to Erlang crypto documentation for additional details about these two functions.
Important
Note: mbedTLS doesn’t support padding for ciphers other than CCB, so block size must be accounted otherwise output will be truncated.
ESP32-specific APIs
Certain APIs are specific to and only supported on the ESP32 platform. This section describes these APIs.
System-Level APIs
As noted above, the erlang:system_info/1 function can be used to obtain system-specific information about the platform on which your application is deployed.
You can request ESP32-specific information using using the following input atoms:
esp32_free_heap_sizeReturns the available free space in the ESP32 heap.esp32_largest_free_blockReturns the size of the largest free continuous block in the ESP32 heap.esp32_minimum_free_sizeReturns the smallest ever free space available in the ESP32 heap since boot, this will tell you how close you have come to running out of free memory.esp32_chip_infoReturns map of the form#{features := Features, cores := Cores, revision := Revision, model := Model}, whereFeaturesis a list of features enabled in the chip, from among the following atoms:[emb_flash, bgn, ble, bt];Coresis the number of CPU cores on the chip;Revisionis the chip version; andModelis one of the following atoms:esp32,esp32_s2,esp32_s3,esp32_c3, etc.esp_idf_versionReturn the IDF SDK version, as a string.
For example,
FreeHeapSize = erlang:system_info(esp32_free_heap_size).
Non-volatile Storage
AtomVM provides functions for setting, retrieving, and deleting key-value data in binary form in non-volatile storage (NVS) on an ESP device. Entries in NVS survive reboots of the ESP device, and can be used a limited “persistent store” for key-value data.
Warning
NVS storage is limited in size, and NVS keys are restricted to 15 characters. Try to avoid writing frequently to NVS storage, as the flash storage may degrade more rapidly with repeated writes to the medium.
NVS entries are stored under a namespace and key, both of which are expressed as atoms. AtomVM uses the namespace atomvm for entries under its control. Applications may read from and write to the atomvm namespace, but they are strongly discouraged from doing so, except when explicitly stated otherwise.
To set a value in non-volatile storage, use the esp:nvs_set_binary/3 function, and specify a namespace, key, and value:
Namespace = <<"my-namespace">>,
Key = <<"my-key">>,
esp:set_binary(Namespace, Key, <<"some-value">>).
To retrieve a value in non-volatile storage, use the esp:nvs_get_binary/2 function, and specify a namespace and key. You can optionally specify a default value (of any desired type), if an entry does not exist in non-volatile storage:
Value = esp:get_binary(Namespace, Key, <<"default-value">>).
To delete an entry, use the esp:nvs_erase_key/2 function, and specify a namespace and key:
ok = esp:erase_key(Namespace, Key).
You can delete all entries in a namespace via the esp:nvs_erase_all/1 function:
ok = esp:erase_all(Namespace).
Finally, you can delete all entries in all namespaces on the NVS partition via the esp:nvs_reformat/0 function:
ok = esp:reformat().
Applications should use the esp:nvs_reformat/0 function with caution, in case other applications are making using the non-volatile storage.
Caution
NVS entries are currently stored in plaintext and are not encrypted. Applications should exercise caution if sensitive security information, such as account passwords, are stored in NVS storage.
Storage
AtomVM provides support for mounting and unmounting storage on ESP32 devices, such as SD cards or internal flash memory. This functionality is accessible through the esp:mount/4 and esp:umount/1 functions.
Mounting MMC SD card
To mount a MMC SD card, use the esp:mount/4 function:
case esp:mount("sdmmc", "/sdcard", fat, []) of
{ok, MountedRef} ->
io:format("SD card mounted successfully~n"),
{ok, MountedRef};
{error, Reason} ->
io:format("Failed to mount SD card: ~p~n", [Reason]),
{error, Reason}
end.
Mounting SPI SD card
To mount a SPI SD card, first create a SPI instance configured for your specific board, then use the esp:mount/4 function:
SPIConfig = [
{bus_config, [
{miso, 19},
{mosi, 23},
{sclk, 18},
{peripheral, "spi3"}
]}],
SPI = spi:open(SPIConfig),
case esp:mount("sdspi", "/sdcard", fat, [{spi_host, SPI}, {cs, 5}]) of
{ok, MountedRef} ->
io:format("SD card mounted successfully~n"),
{ok, MountedRef};
{error, Reason} ->
io:format("Failed to mount SD card: ~p~n", [Reason]),
{error, Reason}
end.
Mounting internal flash
To mount internal flash, use the esp:mount/4 function:
case esp:mount("/dev/partition/by-name/partition_name", "/test", fat, []) of
{ok, MountedRef} ->
io:format("Flash mounted successfully~n"),
{ok, MountedRef};
{error, Reason} ->
io:format("Failed to mount partition: ~p~n", [Reason]),
{error, Reason}
end.
Unmounting Storage
To unmount a previously mounted storage device, use the esp:umount/1 function, with the reference returned from esp:mount/4:
case esp:umount(MountedRef) of
ok ->
io:format("Storage unmounted successfully~n");
{error, Reason} ->
io:format("Failed to unmount storage: ~p~n", [Reason])
end.
These functions allow you to work with external storage devices or partitions on your ESP32, enabling you to read from and write to files on the mounted filesystem. This can be particularly useful for applications that need to store or access large amounts of data that don’t fit in the device’s main memory or non-volatile storage.
Important
Remember to properly unmount any mounted filesystems before powering off or resetting the device to prevent data corruption.
Restart and Deep Sleep
You can use the esp:restart/0 function to immediately restart the ESP32 device. This function does not return a value.
esp:restart().
Use the esp:reset_reason/0 function to obtain the reason for the ESP32 restart. Possible values include:
esp_rst_unknownesp_rst_poweronesp_rst_extesp_rst_swesp_rst_panicesp_rst_int_wdtesp_rst_task_wdtesp_rst_wdtesp_rst_deepsleepesp_rst_brownoutesp_rst_sdio
Use the esp:deep_sleep/1 function to put the ESP device into deep sleep for a specified number of milliseconds. Be sure to safely stop any critical processes running before this function is called, as it will cause an immediate shutdown of the device.
esp:deep_sleep(60*1000).
Use the esp:sleep_get_wakeup_cause/0 function to inspect the reason for a wakeup. Possible return values include:
sleep_wakeup_ext0sleep_wakeup_ext1sleep_wakeup_timersleep_wakeup_touchpadsleep_wakeup_ulpsleep_wakeup_gpiosleep_wakeup_uartsleep_wakeup_wifisleep_wakeup_cocpusleep_wakeup_cocpu_trag_trigsleep_wakeup_btundefined(no sleep wakeup)error(unknown other reason)
The values matches the semantics of esp_sleep_get_wakeup_cause.
case esp:sleep_get_wakeup_cause() of
sleep_wakeup_timer ->
io:format("Woke up from a timer~n");
sleep_wakeup_ext0 ->
io:format("Woke up from ext0~n");
sleep_wakeup_ext1 ->
io:format("Woke up from ext1~n");
_ ->
io:format("Woke up for some other reason~n")
end.
Use the esp:sleep_enable_ext0_wakeup/2 and esp:sleep_enable_ext1_wakeup/2 functions to configure ext0 and ext1 wakeup mechanisms. They follow the semantics of esp_sleep_enable_ext0_wakeup and esp_sleep_enable_ext1_wakeup.
-spec shutdown() -> no_return().
shutdown() ->
% Configure wake up when GPIO 37 is set to low (M5StickC main button)
ok = esp:sleep_enable_ext0_wakeup(37, 0),
% Deep sleep for 1 hour
esp:deep_sleep(60*60*1000).
RTC Memory
On ESP32 systems, you can use (slow) “real-time clock” memory to store data between deep sleeps. This storage can be useful, for example, to store interim state data in your application.
Important
RTC memory is initialized if power is lost.
To store data in RTC slow memory, use the esp:rtc_slow_set_binary/1 function:
esp:rtc_slow_set_binary(<<"some binary data">>)
To retrieve data in RTC slow memory, use the esp:rtc_slow_get_binary/0 function:
Data = esp:rtc_slow_get_binary()
Caution
Calling esp:rtc_slow_get_binary/0 without having stored a binary first using esp:rtc_slow_set_binary/1, will raise with badarg. So make sure to wrap such a call with a try/catch or similar.
By default, RTC slow memory in AtomVM is limited to 4098 (4k) bytes. This value can be modified at build time using an IDF SDK KConfig setting. For instructions about how to build AtomVM, see the AtomVM Build Instructions.
Miscellaneous ESP32 APIs
esp:freq_hz/0Theesp:freq_hz/0function can be used to retrieve the clock frequency of the chip.esp:partition_list/0Theesp:partition_list/0function can be used to retrieve information about the partitions on an ESP32 flash.
The return type is a list of tuples, each of which contains the partition id (as a binary), partition type and sub-type (both of which are represented as integers), the start of the partition as an address along with its size, as well as a list of properties about the partition, as a properties list.
PartitionList = esp:partition_list(), lists:foreach( fun({ PartitionId, PartitionType, PartitionSubtype, PartitionAddress, PartitionSize, PartitionProperties }) -> %% ... end, PartitionList )Note
The partition properties are currently empty (
[]).See also
For information about the encoding of partition types and sub-types, see the IDF SDK partition type definitions.
esp:get_mac/1Theesp:get_mac/1function can be used to retrieve the network Media Access Control (MAC) address for a given interface,wifi_staorwifi_softap. The return value is a 6-byte binary, in accordance with the IEEE 802 family of specifications.
MacAddress = esp:get_mac(wifi_sta)
Peripherals
The AtomVM virtual machine and libraries support APIs for interfacing with peripheral devices connected to the ESP32 and other supported microcontrollers. This section provides information about these APIs. Unless otherwise stated the documentation for these peripherals is specific to the ESP32, most peripherals are not yet supported on rp2040 or stm32 devices - but work is on-going to expand support for these platforms.
GPIO
The GPIO peripheral has nif support on all platforms. One notable difference on the STM32 platform is that Pin() is defined as a tuple consisting of the bank (a.k.a. port) and pin number. For example a pin labeled PB7 on your board would be {b,7}.
You can read and write digital values on GPIO pins using the gpio module, using the digital_read/1 and digital_write/2 functions. You must first set the pin mode using the gpio:set_pin_mode/2 function, using input or output as the direction parameter.
Digital Read
To read the value of a GPIO pin (high or low), use gpio:digital_read/1.
For ESP32 family:
Pin = 2,
gpio:set_pin_mode(Pin, input),
case gpio:digital_read(Pin) of
high ->
io:format("Pin ~p is high ~n", [Pin]);
low ->
io:format("Pin ~p is low ~n", [Pin])
end.
For STM32 only the line with the Pin definition needs to be a tuple:
Pin = {c, 13},
gpio:set_pin_mode(Pin, input),
case gpio:digital_read(Pin) of
high ->
io:format("Pin ~p is high ~n", [Pin]);
low ->
io:format("Pin ~p is low ~n", [Pin])
end.
The RP2 has an additional initialization step gpio:init/1 before using a pin for gpio:
Pin = 2,
gpio:init(Pin),
gpio:set_pin_mode(Pin, input),
case gpio:digital_read(Pin) of
high ->
io:format("Pin ~p is high ~n", [Pin]);
low ->
io:format("Pin ~p is low ~n", [Pin])
end.
Digital Write
To set the value of a GPIO pin (high or low), use gpio:digital_write/2.
For ESP32 family:
Pin = 2,
gpio:set_pin_mode(Pin, output),
gpio:digital_write(Pin, low).
For the STM32 use a pin tuple:
Pin = {b, 7},
gpio:set_pin_mode(Pin, output),
gpio:digital_write(Pin, low).
RP2 needs the extra gpio:init/1 before gpio:read/1 too:
Pin = 2,
gpio:init(Pin),
gpio:set_pin_mode(Pin, output),
gpio:digital_write(Pin, low).
Interrupt Handling
Interrupts are supported on both the ESP32 and STM32 platforms. They require using the GPIO port driver, using gpio:open/0 and gpio:set_direction/3.
You can get notified of changes in the state of a GPIO pin by using the gpio:set_int/3 function. This function takes a reference to a GPIO instance, a Pin, and a trigger. Allowable triggers are rising, falling, both, low, high, and none (to disable an interrupt).
When a trigger event occurs, such as a pin rising in voltage, a tuple will be delivered to the process that set the interrupt containing the atom gpio_interrupt and the pin.
Pin = 2,
GPIO = gpio:open(),
gpio:set_direction(GPIO, Pin, input),
ok = gpio:set_int(GPIO, Pin, rising),
receive
{gpio_interrupt, Pin} ->
io:format("Pin ~p is rising ~n", [Pin])
end.
You can also use the gpio:set_int/4 function, and specify a listener pid() or registered name as the recipient of interrupt messages as the fourth parameter.
Pin = 2,
GPIO = gpio:open(),
gpio:set_direction(GPIO, Pin, input),
Listener = spawn(fun() -> my_gen_statem() end),
ok = gpio:set_int(GPIO, Pin, rising, Listener),
timer:sleep(infinity).
Interrupts can be removed by using the gpio:remove_int/2 function.
Use the gpio:close/1 function to close the GPIO driver and free any resources in use by it, supplying a reference to a previously opened GPIO driver instance. Any references to the closed GPIO instance are no longer valid after a successful call to this function, and all interrupts will be removed.
ok = gpio:close(GPIO).
Since only one instance of the GPIO driver is allowed, you may also simply use gpio:stop/0 to remove all interrupts, free the resources, and close the GPIO driver port.
ok = gpio:stop().
ESP32 ADC
The esp_adc module provides the functionality to use the ESP32 family SAR ADC peripheral to measure (analog) voltages from a pin and obtain both raw bit values as well as calibrated voltage values in millivolts.
The module provides two sets of APIs for using the ADC peripheral; there is a set of low level resource based nifs, and a gen_server managed set of convenience functions. The nifs rely on unit and channel handle resources for configuring and taking measurements. The convenience functions use the gen_server to maintain these resources and use pin numbers to interact with the driver. Examples for both APIs can be found the AtomVM repository atomvm/examples/erlang/esp32 directory. A demonstration of the simple APIs is as follows:
...
Pin = 33,
ok = esp_adc:start(Pin, [{bitwidth, bit_12}, {atten, db_2_5}]),
{ok, {Raw, Mv}} = esp_adc:read(Pin, [raw, voltage, {samples, 48}]),
io:format("ADC pin ~p raw value=~p millivolts=~p~n", [Pin, Raw, Mv]),
ok = esp_adc:stop(),
...
ESP32 ADC configuration options
Some newer ESP32 family devices only use a single fixed bit width, this is typically 12 bits, but some provide 13 bit resolution. The ESP32 classic supports 9 bit up to 12 bit resolutions. The bitwidth option bit_max will use the highest supported resolution for the device.
The attenuation option determines the range of voltage to be measured, the specific voltage range for each setting varies by chip, so as always consult your devices datasheet before connecting an ADC pin to a voltage supply to be measured. The chart below depicts the approximate safe voltage ranges for each attenuation level:
Attenuation |
Min Millivolts |
Max Millivolts |
|---|---|---|
|
0-100 |
750-950 |
|
0-100 |
1050-1250 |
|
0-150 |
1300-1750 |
|
0-150 |
2450-2500 |
Consult the datasheet of your device for the exact voltage ranges supported by each attenuation level.
Warning
The option db_11 has been superseded by db_12. The option db_11 and will be deprecated in a future release, applications should be updated to use db_12 (except for builds with ESP-IDF versions prior to v5.2). To Continue to support older IDF version builds, the default will remain db_11, which is the maximum tolerated voltage on all builds, as db_12 supported builds will automatically use db_12 in place of db_11. After db_11 is deprecated in all builds (with the sunset of ESP-IDF v5.1 support) the default will be changed to db_12.
Note
For a higher degree of accuracy increase the number of sample taken, the default is 64. If highly stable and accurate ADC measurements are required for an application you may need to connect a bypass capacitor (e.g., a 100 nF ceramic capacitor) to the ADC input pad in use, to minimize noise. This chart from the Espressif ADC Calibration Driver documentation shows the difference between the use of a capacitor and without, as well as with a capacitor and multisampling of 64 samples.
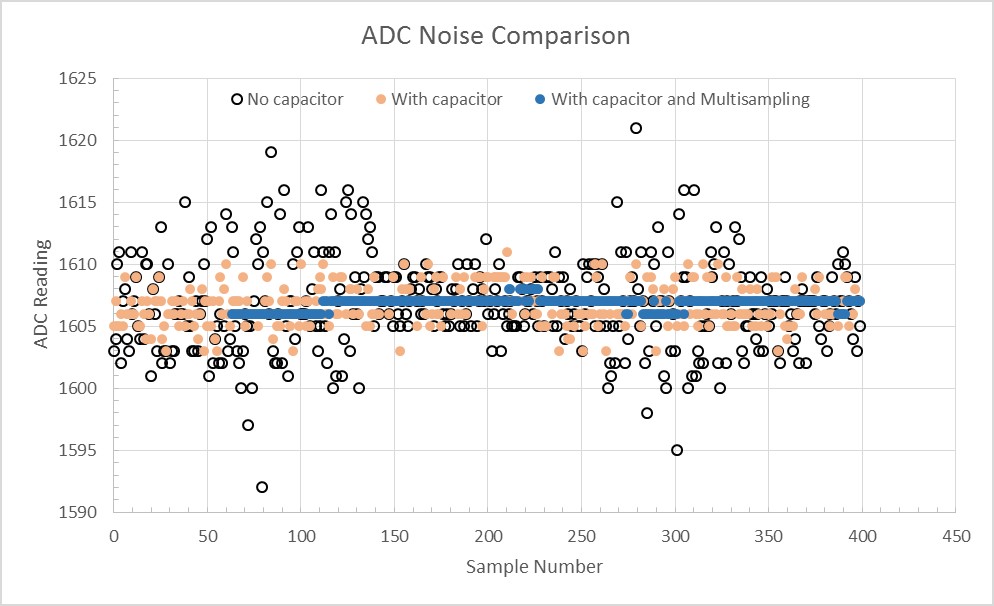
You can clearly see the noisy results without a capacitor. This is mitigated by the use of multisampling but without a decoupling capacitor results will likely still contain some noise.
When an ADC channel is configured by the use of esp_adc:acquire/2,4 or esp_adc:start/1,2 the driver will select the optimal calibration mechanism supported by the device and channel configuration. If neither the line fitting or curve fitting mechanisms are supported by the device using the provided configuration options an estimated result will be used to provide voltage values, based on the formula suggested by Espressif. For chips using the line fitting calibration scheme that do not have the default vref efuse set, a default vref of 1100 mV is used, this is not currently settable.
ESP32 ADC read options
The read options take the form of a proplist, if the key raw is true ({raw, true} or simply appears in the list as the atom raw), then the raw value will be returned in the first element of the returned tuple. Otherwise, this element will be the atom undefined.
If the key voltage is true (or simply appears in the list as an atom), then a calibrated voltage value will be returned in millivolts in the second element of the returned tuple. Otherwise, this element will be the atom undefined.
You may specify the number of samples (1 - 100000) to be taken and averaged over using the tuple {samples, Samples :: 1..100000}, the default is 64.
Warning
Using a large number of samples can significantly increase the amount of time before a response, up to several seconds.
I2C
The i2c module encapsulates functionality associated with the 2-wire Inter-Integrated Circuit (I2C) interface.
See also
Information about the ESP32 I2C interface can be found in the IDF SDK I2C Documentation.
The AtomVM I2C implementation uses the AtomVM Port mechanism and must be initialized using the i2c:open/1 function. The single parameter contains a properties list, with the following elements:
Key |
Value Type |
Required |
Description |
|---|---|---|---|
|
|
yes |
I2C clock pin (SCL) |
|
|
yes |
I2C data pin (SDA) |
|
|
yes |
I2C clock frequency (in hertz) |
|
`string() |
binary()` |
no (platform dependent default) |
For example,
I2C = i2c:open([{scl, 21}, {sda, 22}, {clock_speed_hz, 40000}]),
Once the port is opened, you can use the returned I2C instance to read and write bytes to the attached device.
Both read and write operations require the I2C bus address from which data is read or to which data is written. A devices address is typically hard-wired for the specific device type, or in some cases may be changed by the addition or removal of a resistor.
In addition, you may optionally specify a register to read from or write to, as some devices require specification of a register value. Consult your device’s data sheet for more information and the device’s I2C bus address and registers, if applicable.
There are two patterns for writing data to an I2C device:
Queuing
i2c:write_bytes/2,3,4write operations between calls toi2c:begin_transmission/2andi2c:end_transmission/1. In this case, write operations are queued locally and dispatched to the target device when thei2c:end_transmission/1operation is called;Writing a byte or sequence of bytes in one
i2c:write_bytes/2,3,4operation.
The choice of which pattern to use will depend on the device being communicated with. For example, some devices require a sequence of write operations to be queued and written in one atomic write, in which case the first pattern is appropriate. E.g.,
ok = i2c:begin_transmission(I2C),
ok = i2c:qwrite_bytes(I2C, DeviceAddress, Register1, <<"some sequence of bytes">>),
ok = i2c:qwrite_bytes(I2C, DeviceAddress, Register2, <<"some other of bytes">>),
ok = i2c:end_transmission(I2C),
In other cases, you may just need to write a byte or sequence of bytes in one operation to the device:
ok = i2c:write_bytes(I2C, DeviceAddress, Register1, <<"write it all in one go">>),
Reading bytes is more straightforward. Simply use i2c:read_bytes/3,4, specifying the port instance, device address, optionally a register, and the number of bytes to read:
{ok, BinaryData} = i2c:read_bytes(I2C, DeviceAddress, Register, Len)
To close the I2C driver and free any resources in use by it, use the i2c:close/1 function, supplying a reference to the I2C driver instance created via i2c:open/1:
ok = i2c:close(I2C)
Once the I2C driver is closed, any calls to i2c functions using a reference to the I2C driver instance should return with the value {error, noproc}.
SPI
The spi module encapsulates functionality associated with the 4-wire Serial Peripheral Interface (SPI) in leader mode.
See also
Information about the ESP32 SPI leader mode interface can be found in the IDF SDK SPI Documentation.
The AtomVM SPI implementation uses the AtomVM Port mechanism and must be initialized using the spi:open/1 function. The single parameter to this function is a properties list containing:
bus_config– a properties list containing entries for the SPI busdevice_config– an optional properties list containing entries for each device attached to the SPI Bus
The bus_config properties list contains the following entries:
Key |
Value Type |
Required |
Description |
|---|---|---|---|
|
|
yes |
SPI peripheral-out, controller-in pin (MOSI) |
|
|
yes |
SPI peripheral-in, controller-out pin (MISO) |
|
|
yes |
SPI clock pin (SCLK) |
The device_config entry is a properties list containing entries for each device attached to the SPI Bus. Each entry in this list contains the user-selected name (as an atom) of the device, followed by configuration for the named device.
Each device configuration is a properties list containing the following entries:
Key |
Value Type |
Required |
Description |
|---|---|---|---|
|
|
yes |
SPI clock frequency (in hertz) |
|
|
yes |
SPI mode, indicating clock polarity ( |
|
|
yes |
SPI chip select pin (CS) |
|
|
yes |
number of bits in the address field of a read/write operation (for example, 8, if the transaction address field is a single byte) |
|
|
default: 0 |
number of bits in the command field of a read/write operation (for example, 8, if the transaction command field is a single byte) |
For example,
SPIConfig = [
{bus_config, [
{miso, 19},
{mosi, 27},
{sclk, 5}
]},
{device_config, [
{my_device_1, [
{clock_speed_hz, 1000000},
{mode, 0},
{cs, 18},
{address_len_bits, 8}
]}
{my_device_2, [
{clock_speed_hz, 1000000},
{mode, 0},
{cs, 15},
{address_len_bits, 8}
]}
]}
],
SPI = spi:open(SPIConfig),
...
In the above example, there are two SPI devices, one using pin 18 chip select (named my_device_1), and once using pin 15 chip select (named my_device_2).
Once the port is opened, you can use the returned SPI instance, along with the selected device name, to read and write bytes to the attached device.
To read a byte at a given address on the device, use the spi:read_at/4 function:
{ok, Byte} = spi:read_at(SPI, DeviceName, Address, 8)
To write a byte at a given address on the device, use the spi_write_at/5 function:
write_at(SPI, DeviceName, Address, 8, Byte)
Hint
The spi:write_at/5 takes integer values as inputs and the spi:read_at/4 returns integer values. You may read and
write up to 32-bit integer values via these functions.
Consult your local device data sheet for information about various device addresses to read from or write to, and their semantics.
The above functions are optimized for small reads and writes to an SPI device, typically one byte at a time.
The SPI interface also supports a more generic way to read and write from an SPI device, supporting arbitrary-length reads and writes, as well as a number of different “phases” of writes, per the SPI specification.
These phases include:
Command phase – write of an up-to 16-bit command to the SPI device
Address Phase – write of an up-to 64-bit address to the SPI device
Data Phase – read or write of an arbitrary amount of of data to and from the device.
Any one of these phases may be included or omitted in any given SPI transaction.
In order to achieve this level of flexibility, these functions allow users to specify the SPI transaction through a map structure, which includes fields that specify the behavior of an SPI transaction.
The following table enumerates the permissible fields in this structure:
Key |
Value Type |
Description |
|---|---|---|
|
|
(Optional) SPI command. The low-order |
|
|
(Optional) Device address. The low-order |
|
|
(Optional) Data to write |
|
|
Number of bits to write from `write_data’. If not included,then all bits will be written. |
|
|
Number of bits to read from the SPI device. If not included, then the same number of bits will be read as were written. |
To write a blob of data to the SPI device, for example, you would use:
WriteData = <<"some binary data">>,
ok = spi:write(SPI, DeviceName, #{write_data => WriteData})
To write and simultaneously read back a blob of data to the SPI device, you would use:
{ok, ReadData} = spi:write_read(SPI, DeviceName, #{write_data => WriteData})
The size of the returned data is the same as the size of the written data, unless otherwise specified by the read_bits field.
Use the spi:close/1 function to close the SPI driver and free any resources in use by it, supplying a reference to a previously opened SPI driver instance. Any references to the closed SPI instance are no longer valid after a successful call to this function.
ok = spi:close(SPI).
UART
The uart module encapsulates functionality associated with the Universal Asynchronous Receiver/Transmitter (UART) interface supported on ESP32 devices. Some devices, such as NMEA GPS receivers, make use of this interface for communicating with an ESP32.
See also
Information about the ESP32 UART interface can be found in the IDF SDK UART Documentation.
The AtomVM UART implementation uses the AtomVM Port mechanism and must be initialized using the uart:open/2 function.
The first parameter indicates the ESP32 UART hardware interface. Valid values are:
"UART0" | "UART1" | "UART2"
The second parameter is a properties list, containing the following elements:
Key |
Value Type |
Required |
Default Value |
Description |
|---|---|---|---|---|
|
|
no |
-1 ( |
RX GPIO Pin |
|
|
no |
-1 ( |
TX GPIO Pin |
|
|
no |
115200 |
UART baud rate (bits/sec) |
|
|
no |
8 |
UART data bits |
|
|
no |
1 |
UART stop bits |
|
|
no |
|
Flow control |
|
|
no |
|
UART parity check |
These are the usual RX and TX pins for the various UARTs on the ESP32 (as always check your board specs):
Port |
RX pin |
TX pin |
|---|---|---|
|
GPIO_3 |
GPIO_1 |
|
GPIO_9 |
GPIO_10 |
|
GPIO_16 |
GPIO_17 |
For example,
UART = uart:open("UART0", [{rx, 3}, {tx, 1}, {speed, 9600}])
Once the port is opened, you can use the returned UART instance to read and write bytes to the attached device.
To read data from the UART channel, use the uart:read/1 function. The return value from this function is a binary:
Bin = uart:read(UART)
To write data to the UART channel, use the uart_write/2 function. The input data is any Erlang I/O list:
uart:write(UART, [<<"any">>, $d, $a, $t, $a, "goes", <<"here">>])
Consult your local device data sheet for information about the format of data to be read from or written to the UART channel.
To close the UART driver and free any resources in use by it, use the uart:close/1 function, supplying a reference to the UART driver instance created via uart:open/2:
ok = uart:close(UART)
Once the UART driver is closed, any calls to uart functions using a reference to the UART driver instance should return with the value {error, noproc}.
LED Control
The LED Control API can be used to drive LEDs, as well as generate PWM signals on GPIO pins.
The LEDC API is encapsulated in the ledc module and is a direct translation of the IDF SDK LEDC API, with a natural mapping into Erlang. This API is intended for users with complex use-cases, and who require low-level access to the LEDC APIs.
The ledc.hrl module should be used for common modes, channels, duty cycle resolutions, and so forth.
-include("ledc.hrl").
%% create a 5khz timer
SpeedMode = ?LEDC_HIGH_SPEED_MODE,
Channel = ?LEDC_CHANNEL_0,
ledc:timer_config([
{duty_resolution, ?LEDC_TIMER_13_BIT},
{freq_hz, 5000},
{speed_mode, ?LEDC_HIGH_SPEED_MODE},
{timer_num, ?LEDC_TIMER_0}
]).
%% bind pin 2 to this timer in a channel
ledc:channel_config([
{channel, Channel},
{duty, 0},
{gpio_num, 2},
{speed_mode, ?LEDC_HIGH_SPEED_MODE},
{hpoint, 0},
{timer_sel, ?LEDC_TIMER_0}
]).
%% set the duty cycle to 0, and fade up to 16000 over 5 seconds
ledc:set_duty(SpeedMode, Channel, 0).
ledc:update_duty(SpeedMode, Channel).
TargetDuty = 16000.
FadeMs = 5000.
ok = ledc:set_fade_with_time(SpeedMode, Channel, TargetDuty, FadeMs).
Protocols
AtomVM supports network programming on devices that support it, specifically the ESP32 platform, with its built-in support for WIFI networking, and of course on the UNIX platform.
This section describes the network programming APIs available on AtomVM.
Network (ESP32 only)
The ESP32 supports WiFi connectivity as part of the built-in WiFi and Bluetooth radio (and in most modules, an integrated antenna). The WIFI radio on an ESP32 can operate in several modes:
STA (Station) mode, whereby it acts as a member of an existing WiFi network;
AP (Access Point) mode, whereby the ESP32 acts as an access point for other devices; or
AP+STA mode, whereby the ESP32 behaves both as a member of an existing WiFi network and as an access point for other devices.
AtomVM supports these modes of operation via the network module, which is used to initialize the network and allow applications to respond to events within the network, such as a network disconnect or reconnect, or a connection to the ESP32 from another device.
See also
Establishment and maintenance of network connections on roaming devices is a complex and subtle art, and the AtomVM
network module is designed to accommodate as many IoT scenarios as possible. This section of the programmer’s guide
is deliberately brief and only addresses the most basic scenarios. For a more detailed explanation of the AtomVM
network module and its many use-cases, please refer to the AtomVM Network Programming Guide.
STA mode
To connect your ESP32 to an existing WiFi network, use the network:wait_for_sta/1,2 convenience function, which abstracts away some of the more complex details of ESP32 STA mode.
This function takes a station mode configuration, as a properties list, and optionally a timeout (in milliseconds) before connecting to the network should fail. The default timeout, if unspecified, is 15 seconds.
The station mode configuration supports the following options:
Key |
Value Type |
Required |
Default Value |
Description |
|---|---|---|---|---|
|
|
yes |
- |
WiFi AP SSID |
|
|
yes, if network is encrypted |
- |
WiFi AP password |
|
|
no |
|
DHCP hostname for the connecting device |
Important
The WiFi network to which you are connecting must support DHCP and IPv4. IPv6 addressing is not yet supported on AtomVM.
If the ESP32 device connects to the specified network successfully, the device’s assigned address, netmask, and gateway address will be returned in an {ok, ...} tuple; otherwise, an error is returned.
For example:
Config = [
{ssid, <<"myssid">>},
{psk, <<"mypsk">>},
{dhcp_hostname, <<"mydevice">>}
],
case network:wait_for_sta(Config, 15000) of
{ok, {Address, _Netmask, _Gateway}} ->
io:format("Acquired IP address: ~p~n", [Address]);
{error, Reason} ->
io:format("Network initialization failed: ~p~n", [Reason])
end
Once connected to a WiFi network, you may begin TCP or UDP networking, as described in more detail below.
For information about how to handle disconnections and re-connections to a WiFi network, see the AtomVM Network Programming Guide.
AP mode
To turn your ESP32 into an access point for other devices, you can use the network:wait_for_ap/1,2 convenience function, which abstracts away some of the more complex details of ESP32 AP mode. When the network is started, the ESP32 device will assign itself the 192.168.4.1 address. Any devices that connect to the ESP32 will take addresses in the 192.168.4/24 network.
This function takes an access point mode configuration, as a properties list, and optionally a timeout (in milliseconds) before starting the network should fail. The default timeout, if unspecified, is 15 seconds.
The access point mode configuration supports the following options:
Key |
Value Type |
Required |
Default Value |
Description |
|---|---|---|---|---|
|
|
no |
|
WiFi AP SSID |
|
|
no |
|
Whether the AP SSID should be hidden (i.e., not broadcast) |
|
|
yes, if network is encrypted |
- |
WiFi AP password. Warning: If this option is not specified, the network will be an open network, to which anyone who knows the SSID can connect and which is not encrypted. |
|
|
no |
|
Maximum number of devices that can be connected to this AP |
If the ESP32 device starts the AP network successfully, the ok atom is returned; otherwise, an error is returned.
For example:
Config = [
{psk, <<"mypsk">>}
],
case network:wait_for_ap(Config, 15000) of
ok ->
io:format("AP network started at 192.168.4.1~n");
{error, Reason} ->
io:format("Network initialization failed: ~p~n", [Reason])
end
Once the WiFi network is started, you may begin TCP or UDP networking, as described in more detail below.
For information about how to handle connections and disconnections from attached devices, see the AtomVM Network Programming Guide.
STA+AP mode
For information about how to run the AtomVM network in STA and AP mode simultaneously, see the AtomVM Network Programming Guide.
SNTP
For information about how to use SNTP to synchronize the clock on your device, see the AtomVM Network Programming Guide.
UDP
AtomVM supports network programming using the User Datagram Protocol (UDP) via the gen_udp module. This modules obeys the syntax and semantics of the Erlang/OTP gen_udp interface.
Attention
Not all of the Erlang/OTP gen_udp functionality is implemented in AtomVM. For details, consult the
AtomVM API documentation.
To open a UDP port, use the gen_udp:open/1,2 function. Supply a port number, and if your application plans to receive UDP messages, specify that the port is active via the {active, true} property in the optional properties list.
For example:
Port = 44404,
case gen_udp:open(Port, [{active, true}, binary]) of
{ok, Socket} ->
{ok, SockName} = inet:sockname(Socket)
io:format("Opened UDP socket on ~p.~n", [SockName])
Error ->
io:format("An error occurred opening UDP socket: ~p~n", [Error])
end
If the port is active, you can receive UDP messages in your application. They will be delivered as a 5-tuple, starting with the udp atom, and containing the socket, address and port from which the message was sent, as well as the datagram packet, itself, as a list (by default) or a binary. To choose the format, pass list or binary in options, as with Erlang/OTP.
receive
{udp, _Socket, Addr, Port, Packet} ->
io:format("Received UDP packet ~p from address ~p port ~p~n", [Packet, Addr, Port])
end,
With a reference to a UDP Socket, you can send messages to a target UDP endpoint using the gen_udp:send/4 function. Specify the UDP socket returned from gen_udp:open/1,2, the address (as a 4-tuple of octets), port number, and the datagram packet to send:
Packet = <<":アトムVM">>,
Address = {192, 168, 1, 101},
Port = 44404,
case gen_udp:send(Socket, Address, Port, Packet) of
ok ->
io:format("Sent ~p~n", [Packet]);
Error ->
io:format("An error occurred sending a packet: ~p~n", [Error])
end
Important
IPv6 networking is not currently supported in AtomVM.
TCP
AtomVM supports network programming using the Transport Connection Protocol (TCP) via the gen_tcp module. This modules obeys the syntax and semantics of the Erlang/OTP gen_tcp interface.
Attention
Not all of the Erlang/OTP gen_tcp functionality is implemented in AtomVM. For details, consults the
AtomVM API documentation.
Server-side TCP
Server side TCP requires opening a listening socket, and then waiting to accept connections from remote clients. Once a connection is established, the application may then use a combination of sending and receiving packets over the established connection to or from the remote client.
Attention
Programming TCP on the server-side using the gen_tcp interface is a subtle
art, and this portion of the documentation will not go into all of the design choices available when designing a TCP
application.
Start by opening a listening socket using the gen_tcp:listen/2 function. Specify the port number on which the TCP server should be listening:
case gen_tcp:listen(44405, []) of
{ok, ListenSocket} ->
{ok, SockName} = inet:sockname(Socket),
io:format("Listening for connections at address ~p.~n", [SockName]),
spawn(fun() -> accept(ListenSocket) end);
Error ->
io:format("An error occurred listening: ~p~n", [Error])
end.
In this particular example, the server will spawn a new process to wait to accept a connection from a remote client, by calling the gen_tcp:accept/1 function, passing in a reference to the listening socket. This function will block until a client has established a connection with the server.
When a client connects, the function will return a tuple {ok, Socket}, where Socket is a reference to the connection between the client and server:
accept(ListenSocket) ->
io:format("Waiting to accept connection...~n"),
case gen_tcp:accept(ListenSocket) of
{ok, Socket} ->
{ok, SockName} = inet:sockname(Socket),
{ok, Peername} = inet:peername(Socket),
io:format("Accepted connection. local: ~p peer: ~p~n", [SockName, Peername]),
spawn(fun() -> accept(ListenSocket) end),
echo();
Error ->
io:format("An error occurred accepting connection: ~p~n", [Error])
end.
Note
Note that immediately after accepting a connection, this example code will spawn a new process to accept any new connections from other clients.
The socket returned from gen_tcp:accept/1 can then be used to send and receive messages to the connected client:
echo() ->
io:format("Waiting to receive data...~n"),
receive
{tcp_closed, _Socket} ->
io:format("Connection closed.~n"),
ok;
{tcp, Socket, Packet} ->
{ok, Peername} = inet:peername(Socket),
io:format("Received packet ~p from ~p. Echoing back...~n", [Packet, Peername]),
gen_tcp:send(Socket, Packet),
echo()
end.
In this case, the server program will continuously echo the received input back to the client, until the client closes the connection.
For more information about the gen_tcp server interface, consult the AtomVM API Reference Documentation.
Client-side TCP
Client side TCP requires establishing a connection with an endpoint, and then using a combination of sending and receiving packets over the established connection.
Start by opening a connection to another TCP endpoint using the gen_tcp:connect/3 function. Supply the address and port of the TCP endpoint.
For example:
Address = {192, 168, 1, 101},
Port = 44405,
case gen_tcp:connect(Address, Port, []) of
{ok, Socket} ->
{ok, SockName} = inet:sockname(Socket),
{ok, Peername} = inet:peername(Socket),
io:format("Connected to ~p from ~p~n", [Peername, SockName]);
Error ->
io:format("An error occurred connecting: ~p~n", [Error])
end
Once a connection is established, you can use a combination of
SendPacket = <<":アトムVM">>,
case gen_tcp:send(Socket, SendPacket) of
ok ->
receive
{tcp_closed, _Socket} ->
io:format("Connection closed.~n"),
ok;
{tcp, _Socket, ReceivedPacket} ->
{ok, Peername} = inet:peername(Socket),
io:format("Received ~p from ~p~n", [ReceivedPacket, Peername])
end;
Error ->
io:format("An error occurred sending a packet: ~p~n", [Error])
end.
For more information about the gen_tcp client interface, consults the AtomVM API documentation.
Socket Programming
AtomVM supports a subset of the OTP socket interface, giving users more fine-grained control in socket programming.
The OTP socket APIs are relatively new (they were introduced in OTP 22 and have seen revisions in OTP 24). These APIs broadly mirror the BSD Sockets API, and should be familiar to most programmers who have had to work with low-level operating system networking interfaces. AtomVM supports a strict subset of the OTP APIs. Future versions of AtomVM may add additional coverage of these APIs.
The following types are relevant to this interface and are referenced in the remainder of this section:
-type domain() :: inet.
-type type() :: stream | dgram.
-type protocol() :: tcp | udp.
-type socket() :: any().
-type sockaddr() :: sockaddr_in().
-type sockaddr_in() :: #{
family := inet,
port := port_number(),
addr := any | loopback | in_addr()
}.
-type in_addr() :: {0..255, 0..255, 0..255, 0..255}.
-type port_number() :: 0..65535.
-type socket_option() :: {socket, reuseaddr} | {socket, linger}.
Create a socket using the socket:open/3 function, providing a domain, type, and protocol. Currently, AtomVM supports the inet domain, stream and dgram types, and tcp and udp protocols.
For example:
{ok, Socket} = socket:open(inet, stream, tcp),
Server-side TCP Socket Programming
To program using sockets on the server side, you can bind an opened socket to an address and port number using the socket:bind/2 function, supplying a map that specifies the address and port number.
This map may contain the following entries:
Key |
Type |
Default |
Description |
|---|---|---|---|
|
|
The address family. (Currently, only |
|
|
|
The address to which to bind. The |
|
|
|
The port to which to bind the socket. If no port is specified, the operating system will choose a port for the user. |
For example:
PortNumber = 8080,
ok = socket:bind(Socket, #{family => inet, addr => any, port => PortNumber}),
To listen for connections, use the socket:listen/1 function:
ok = socket:listen(Socket),
Once your socket is listening on an interface and port, you can wait to accept a connection from an incoming client using the socket:accept/1 function.
This function will block the current execution context (i.e., Erlang process) until a client establishes a TCP connection with the server:
{ok, ConnectedSocket} = socket:accept(Socket),
Tip
Many applications will spawn processes to listen for socket connections, so that the main execution context of your application is not blocked.
Client-side TCP Socket Programming
To program using sockets on the client side, you can connect an opened socket to an address and port number using the socket:connect/2 function, supplying a map that specifies the address and port number.
This map may contain the following entries:
Key |
Type |
Default |
Description |
|---|---|---|---|
|
|
The address family. (Currently, only |
|
|
|
The address to which to connect. The |
|
|
|
The port to which to connect the socket. |
ok = socket:connect(Socket, #{family => inet, addr => loopback, port => 44404})
Sending and Receiving Data
Once you have a connected socket (either via socket:connect/2 or socket:accept/1), you can send and receive data on that socket using the socket:send/2 and socket:recv/1 functions. Like the socket:accept/1 function, these functions will block until data is sent to a connected peer (or until the data is written to operating system buffers) or received from a connected peer.
The socket:send/2 function can take a binary blob of data or an io-list, containing binary data.
For example, a process that receives data and echos it back to the connected peer might be implemented as follows:
case socket:recv(ConnectedSocket) of
{ok, Data} ->
case socket:send(ConnectedSocket, Data) of
ok ->
io:format("All data was sent~n");
{ok, Rest} ->
io:format("Some data was sent. Remaining: ~p~n", [Rest]);
{error, Reason} ->
io:format("An error occurred sending data: ~p~n", [Reason])
end;
{error, closed} ->
io:format("Connection closed.~n");
{error, Reason} ->
io:format("An error occurred waiting on a connected socket: ~p~n", [Reason])
end.
The socket:recv/1 function will block the current process until a packet has arrived or until the local or remote socket has been closed, or some other error occurs.
Note that the socket:send/2 function may return ok if all of the data has been sent, or {ok, Rest}, where Rest is the remaining part of the data that was not sent to the operating system. If the supplied input to socket:send/2 is an io-list, then the Rest will be a binary containing the rest of the data in the io-list.
Getting Information about Connected Sockets
You can obtain information about connected sockets using the socket:sockname/1 and socket:peername/1 functions. Supply the connected socket as a parameter. The address and port are returned in a map structure
For example:
{ok, #{addr := LocalAddress, port := LocalPort}} = socket:sockname(ConnectedSocket),
{ok, #{addr := PeerAddress, port := PeerPort}} = socket:peername(ConnectedSocket),
Closing and Shutting down Sockets
Use the socket:close/1 function to close a connected socket:
ok = socket:close(ConnectedSocket)
Attention
Data that has been buffered by the operating system may not be delivered, when a socket is closed via the close/1
operation.
For a more controlled way to close full-duplex connected sockets, use the socket:shutdown/2 function. Provide the atom read if you only want to shut down the reads on the socket, write if you want to shut down writes on the socket, or read_write to shut down both reads and writes on a socket. Subsequent reads or writes on the socket will result in an einval error on the calls, depending on how the socket has been shut down.
For example:
ok = socket:shutdown(Socket, read_write)
Setting Socket Options
You can set options on a socket using the socket:setopt/3 function. This function takes an opened socket, a key, and a value, and returns ok if setting the option succeeded.
Currently, the following options are supported:
Option Key |
Option Value |
Description |
|---|---|---|
|
|
Sets |
|
|
Sets |
|
|
Sets the default buffer size (in bytes) on receive calls. This value is only used if the |
For example:
ok = socket:setopt(Socket, {socket, reuseaddr}, true),
ok = socket:setopt(Socket, {socket, linger}, #{onoff => true, linger => 0}),
ok = socket:setopt(Socket, {otp, rcvbuf}, 1024),
UDP Socket Programming
You can use the socket interface to send and receive messages over the User Datagram Protocol (UDP), in addition to TCP.
To use UDP sockets, open a socket using the dgram type and udp protocol.
For example:
{ok, Socket} = socket:open(inet, dgram, udp)
To listen for UDP connections, use the socket:bind/2 function, as described above.
For example:
PortNumber = 512,
ok = socket:bind(Socket, #{family => inet, addr => any, port => PortNumber}),
Use the socket:recvfrom/1 function to receive UDP packets from clients on your network. When a packet arrives, this function will return the received packet, as well as the address of the client that sent the packet.
For example:
case socket:recvfrom(dSocket) of
{ok, {From, Packet}} ->
io:format("Received packet ~p from ~p~n", [Packet, From]);
{error, Reason} ->
io:format("Error on recvfrom: ~p~n", [Reason])
end;
Important
The socket:recvfrom/1 function will block the current process until a packet has arrived or until the local or
remote socket has been closed, or some other error occurs.
Use the socket:sendto/3 function to send UDP packets to a specific destination. Specify the socket, data, and destination address you would like the packet to be delivered to.
For example:
Dest = #{family => inet, addr => loopback, port => 512},
case socket:sendto(Socket, Data, Dest) of
ok ->
io:format("Send packet ~p to ~p.~n", [Data, Dest]);
{ok, Rest} ->
io:format("Send packet ~p to ~p. Remaining: ~p~n", [Data, Dest, Rest]);
{error, Reason} ->
io:format("An error occurred sending a packet: ~p~n", [Reason])
end
Close a UDP socket just as you would a TCP socket, as described above.
Miscellaneous Networking APIs
You can retrieve information about hostnames and services using the net:getaddrinfo/1 and net:getaddrinfo/2 functions. The return value is a list of maps each of which contains address information about the host, including its family (inet), protocol (tcp or udp), type (stream or dgram), and the address, currently an IPv4 tuple.
Important
Currently, the net:getaddrinfo/1,2 functions only supports reporting of IPv4 addresses.
For example:
{ok, AddrInfos} = net:getaddrinfo("www.atomvm.net"),
lists:foreach(
fun(AddrInfo) ->
#{
family := Family,
protocol := Protocol,
type := Type,
address := Address
} = AddrInfo,
io:format(
"family: ~p protocol: ~p type: ~p address: ~p", [Family, Protocol, Type, Address]
)
end,
AddrInfos
),
The host parameter can be a domain name (typically) or a dotted pair IPv4 address.
The returned map contains the network family (currently, only inet is supported), the protocol, type, and address of the host.
The address is itself a map, containing the family, port and IPv4 address of the requested host, e.g.,
#{family => inet, port => 0, addr => {192, 168, 212, 153}}
Note
The OTP documentation states that the address is returned
under the address key in the address info map. However, OTP appears to use addr as the key. For compatibility
with OTP 22 ff., AtomVM supports both the address and addr keys in this map (they reference the same inner map).
If you want to narrow the information you get back to a specific service type, you can specify a service name or port number (as a string value) as the second parameter:
{ok, AddrInfos} = net:getaddrinfo("www.atomvm.net", "https"),
...
Service names are well-known identifiers on the internet, but they may vary from operating system to operating system. See the services(3) man pages for more information.
Note
Narrowing results via the service parameter is not supported on all platforms. In the case where it is not supported, AtomVM will resort to retrying the request without the service parameter.
Where to go from here
For more examples of how to use the AtomVM APIs check out the AtomVM Example Programs.
If you have not already, you may want to read the chapter on AtomVM Tooling to help you get your applications built and flashed to a microcontroller.